
DataNode(DN) is third/last domain in HDFS architecture, which is responsible for storing and retrieving the actual data. In DataNode, data is simply written to multiple machines in the highly distributed mode.
A very large number of independently spinning disks performing huge sequential I/O operations with independent I/O queues can actually outperform RAID in the specific use case of Hadoop workloads. Typically, DataNodes have a large number of independent disks, each of which stores full blocks.
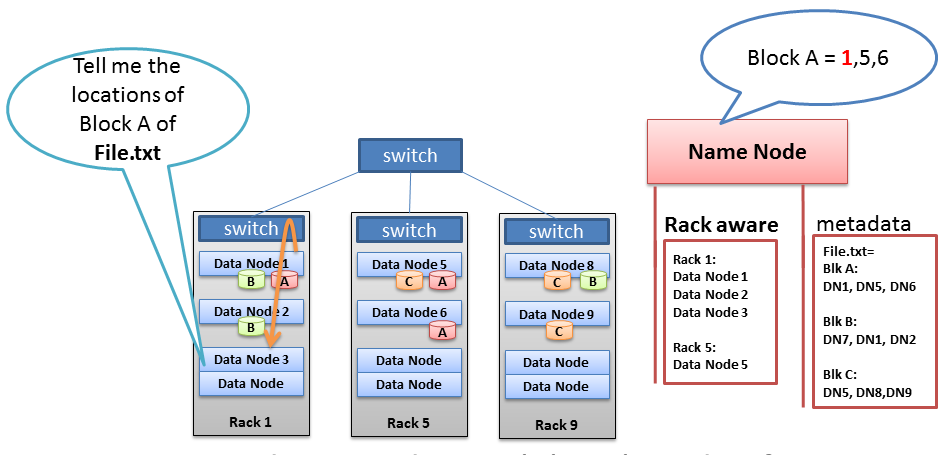
In general, Blocks are nothing more than chunks of a file, binary blobs of data. The DataNode has direct local access to one or more disks—commonly called data disks in a server on which itz permitted to store block data.
Point DataNode to new disks in existing servers or adding new servers with more disks increases the amount of storage in the cluster. Block data is streamed to and from DataNode directly, so bandwidth is not limited by a single node. These blocks are then replicated across the different nodes (DataNodes) in the cluster. The default replication value is 3, i.e. there will be 3 copies of the same block in the cluster
DataNodes regularly report their status to the NameNode in a heartbeat. DataNode initially starts up, as well as every hour thereafter, a block report to the NameNode. A block report is simply a list of all blocks the DataNode currently has on its disks. The NameNode keeps track of all the changes.
In the nutshell, DataNode is the actual storage platform, which manages the file blocks within the node.
Thanks Edward
ReplyDeleteWell said Nikisha
ReplyDeleteThe main motive of the Google cloud big data services is to spread the knowledge so that they can give more big data engineers to the world.
ReplyDeleteTrue Alfred
Delete